



Accélérer le chargement des fichiers, une page à la fois





Les fichiers Figma sont souvent volumineux et complexes, avec une infinité de pages, de bibliothèques, de composants locaux et d'écrans prototypes. Voici comment le chargement dynamique des pages a permis de réduire de 33 % les temps de chargement les plus lents.
Partager Accélérer le chargement des fichiers, une page à la fois
Illustrations par María Medem
Pour les 5 % de pages les plus lentes, nous avons constaté une diminution de 33 % des temps de chargement.
Chaque équipe d'ingénieurs veut que son produit soit rapide. En plus d'offrir aux utilisateurs la meilleure expérience possible, la rapidité de chargement d'un produit influence considérablement leurs premières impressions. Cela estd'autant plus vrai pour nous ; les utilisateurs passent souvent toute leur journée de travail sur Figma, donc les améliorations incrémentales de performance qui permettent de gagner quelques secondes s'additionnent au cours d'une journée de travail. Au fur et à mesure que les équipes produits de Figma développent de nouvelles fonctionnalités et que les utilisateurs ajoutent du contenu à leurs fichiers, nos équipes en charge de la plateforme s'efforcent de maintenir et d'améliorer les performances. Notre tendance idéale en matière de temps de chargement est à la baisse : nous voulons que les temps de chargement des fichiers diminuent au fil du temps, même si la taille des fichiers augmente.
Les performances doivent correspondre à la complexité perçue par l'utilisateur. Si un utilisateur charge une page avec seulement quelques frames, Figma doit pouvoir afficher son plan de travail presque instantanément, même si le fichier contient des dizaines d'autres pages avec des centaines de frames chacune. En examinant les schémas d'utilisation, nous avons remarqué que de nombreux utilisateurs traitaient les fichiers comme des projets, utilisant un fichier pour héberger tous les aspects d'un flux de travail, et que la plupart d'entre eux ne naviguaient même pas vers toutes les pages au cours d'une même session. Nous avons compris que nous pouvions améliorer considérablement les temps de chargement et réduire la mémoire en chargeant dynamiquement le contenu au fur et à mesure des besoins, plutôt qu'en remplissant tout le contenu en une seule fois.
Comprendre les dépendances en lecture dans notre modèle de données
Le chargement dynamique en tant qu'optimisation des performances n'est pas un concept nouveau, mais nous devions relever quelques défis spécifiques à la structure des fichiers de Figma basés sur un navigateur. De manière générale, un fichier Figma est un arbre de nœuds, dans lequel chaque nœud est un calque interchangeable avec des propriétés. Il est important de noter que certains nœuds peuvent faire référence à des nœuds situés sur d'autres pages. Cela signifie qu'il peut y avoir un certain nombre de dépendances entre les pages et les nœuds, des plus évidentes aux plus complexes, que nous avons dû prendre en compte.
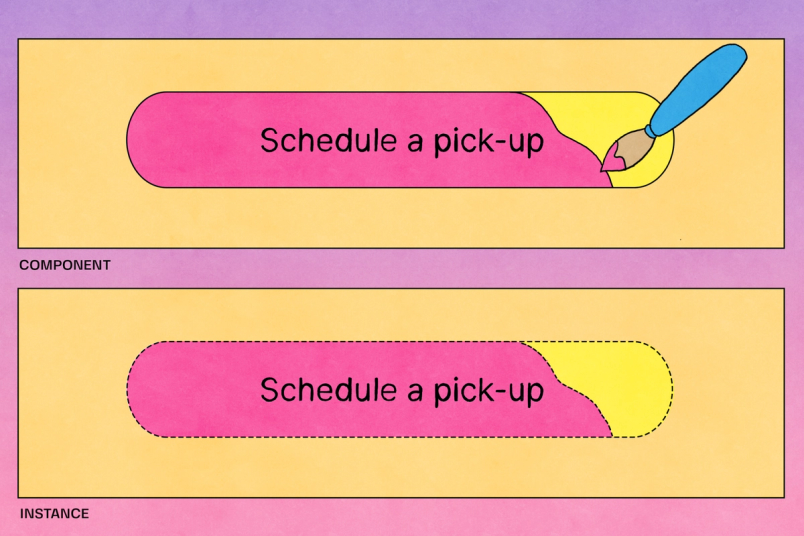
Dans le modèle de données de Figma, une instance contient un pointeur vers un autre nœud, le composant d'appui de l'instance, qui peut se trouver sur une autre page. Nous appelons cette arête une dépendance en lecture, dans laquelle l'instance a une dépendance en lecture sur le composant. Afin de restituer correctement l'instance, le client doit d'abord télécharger le nœud du composant.
Les composants sont des éléments que vous pouvez réutiliser dans vos designs. Ils permettent de créer et de gérer des designs cohérents d'un projet à l'autre. Une instance est une copie liée du composant, qui reçoit automatiquement toutes les mises à jour apportées au composant.
Outre les composants et les instances, de nombreuses fonctionnalités de Figma impliquent des dépendances en lecture. Par exemple, Figma implémente les styles en tant que nœuds invisibles pour l'utilisateur. Si un frame utilise le style de remplissage « BrandPrimary » #FFD966, pour restituer le frame, le client doit d'abord télécharger le nœud de style correspondant. Les variables sont similaires. Si un nœud applique une variable de taille « text-subheader » à sa taille de police, le client doit accéder au nœud de variable afin de résoudre la valeur brute correcte (par exemple, 16) pour la taille de la police.
S'appuyer sur le chargement dynamique pour les visionneuses
Les itérations antérieures de chargement dynamique pour les fichiers en lecture seule et les prototypes nous ont permis de relever ces défis. Nous avons créé un cadre de dépendance appelé QueryGraph, représenté par un graphe en mémoire d'arêtes entre les nœuds dépendants, le composant de la technologie multi-utilisateurs de Figma qui garde la trace de la partie d'un fichier à envoyer aux clients connectés. QueryGraph et son graphe de dépendances en lecture ont permis d'accélérer le chargement des fichiers et des prototypes pour les utilisateurs en lecture seule. Dans chaque cas, l'unité de chargement dynamique correspond au type de contenu que nous rendons lors du chargement initial du fichier :
- Par page dans le plan de travail Figma : au lieu de charger le fichier entier, Figma commence par charger uniquement la page sélectionnée et charge les pages supplémentaires à la demande. En utilisant QueryGraph, le système multi-utilisateurs de Figma envoie la page demandée au client, ainsi que toutes les dépendances en lecture nécessaires sur d'autres pages.
- Par frame dans les prototypes : Figma charge dynamiquement par frame pour les visionneuses de prototypes, où il n'affiche qu'un seul écran à la fois. Figma précharge également les frames que vous pouvez atteindre dans un certain nombre de transitions à partir de votre état actuel afin d'éviter tout décalage perceptible. Là encore, QueryGraph s'assure que le client dispose de toutes les parties requises du fichier Figma et rien d'autre.
Alors que les visionneuses profitent des avantages du chargement dynamique, 70 % de nos chargements quotidiens de fichiers proviennent de fichiers modifiables. Nous voulions tirer parti de notre succès dans le chargement dynamique des prototypes par frame et des fichiers en lecture seule par page, en étendant cette même logique de chargement aux fichiers modifiables. Le défi consistait à s'assurer que les modifications se propagent correctement dans le contenu non chargé lorsqu'une modification affecte des composants sur des pages qui n'ont pas encore été chargées. Pour que cette optimisation profite à tous, nous ne pouvions pas nous contenter de réutiliser la logique existante pour les clients en lecture seule. Pour rendre disponible le chargement dynamique aux éditeurs, nous avons dû étendre notre système de suivi des dépendances afin de prendre en charge un nouveau type d'arête.

Démêler les dépendances en écriture
Alors que la visualisation ou la restitution de parties d'un fichier Figma nécessite des dépendances en lecture, l'écriture ou l'édition de parties d'un fichier nécessite des dépendances en écriture ; dans de nombreux cas, une dépendance en écriture est l'inverse d'une dépendance en lecture existante. Ceci est dû au fait que Figma met en cache le résultat de calculs coûteux tels que l'algorithme de mise en page du texte. Si le style change, Figma exécutera à nouveau la mise en page du texte et mettra en cache le résultat des données dérivées afin qu'il soit toujours prêt pour la restitution. Par exemple, si un style de texte contrôle la police d'un calque de texte, il s'agit d'une dépendance en lecture du calque de texte vers le nœud de style. L'inverse est une dépendance en écriture : le nœud de style a une dépendance en écriture sur le calque de texte, ce qui indique que pour éditer le nœud de style en toute sécurité, Figma a besoin du calque de texte en aval.
Cela est essentiel pour prendre en charge le chargement dynamique pour les éditeurs. Lorsqu'un utilisateur modifie une partie d'un fichier Figma, par exemple en changeant le style du texte, le client doit avoir accès à tous les objets en aval qui nécessitent une mise à jour, comme les informations de glyphe mises en cache d'un calque de texte.
Voici quelques exemples de dépendances en écriture dans le modèle de données de Figma :
- Un composant possède des dépendances en écriture sur toutes ses instances, qui peuvent se trouver sur d'autres pages. Lorsqu'un utilisateur modifie un composant, Figma doit propager et mettre à jour les caches des instances du composant. Il en va de même pour les styles de texte et les variables.
- La mise en page automatique signifie que la modification de la taille ou de la position d'un nœud peut également modifier la taille et la position d'un autre nœud. Il s'agit donc également d'une dépendance en écriture. Avec les composants et les instances, cette dépendance en écriture de la mise en page automatique peut s'étendre sur plusieurs pages. (Par exemple, la mise à jour d'un composant sur une page peut entraîner le redimensionnement d'une instance sur une autre, ce qui peut à son tour entraîner le redimensionnement ou la réorganisation des éléments frères de l'instance dans un frame de mise en page automatique).

Variations sur un thème
Bien que nous ayons envisagé différentes approches du chargement dynamique pour les éditeurs, l'une d'entre elles était clairement privilégiée : le calcul des dépendances en écriture, ce qui impliquerait de mettre à jour le système multi-utilisateurs de Figma pour prendre en compte les dépendances en écriture. Cette approche est similaire à celle que nous avons adoptée pour les utilisateurs en lecture seule et les dépendances en lecture, mais les cas en lecture seule sont intrinsèquement moins risqués. Si la logique de chargement pour les utilisateurs en lecture seule est erronée, alors que les visionneuses peuvent voir un fichier incorrect, l'intégrité du fichier elle-même n'est pas en danger. En revanche, dans les cas d'utilisation en mode modification, si la logique de chargement n'inclut pas les dépendances correctes, le fait de corrompre les données du fichier peut engendrer des incohérences dans les données. (Imaginez que vous fassiez une modification et que vous ne la voyiez jamais reflétée sur une autre page !) Étant donné la complexité de la définition des dépendances en écriture, nous avons également envisagé deux autres solutions alternatives plus simples : la modification et le rechargement différés, ainsi que la refonte du modèle de données.
Modification et rechargement différés
Cette approche impliquerait le chargement de la première page en utilisant la même logique que le chargement dynamique pour les visionneuses. Une fois la première page chargée, l'utilisateur pourrait effectuer des panoramiques, des zooms et inspecter son contenu. En arrière-plan, Figma continuerait à charger le fichier complet comme il le fait aujourd'hui. L'inconvénient est que le fichier serait en lecture seule jusqu'à ce que le reste du fichier soit téléchargé, ce qui pourrait entraîner un délai entre le moment où l'utilisateur souhaite effectuer une modification et le moment où il peut le faire. Cela pourrait également introduire une logique de chargement complexe : nous devrions continuer à charger des pages en arrière-plan, tout en étant en mesure de faire remonter une page au début de la file d'attente de chargement si un utilisateur navigue jusqu'à celle-ci. Pouvoir recharger une telle quantité de données sans introduire de décalage de frames ou de décalage perceptible pour l'utilisateur constituerait un défi.
Refonte du modèle de données
Les dépendances en écriture représentent des données dérivées. Lorsqu'un utilisateur modifie une dépendance, nos systèmes actuels utilisent un modèle basé sur l'intégration pour propager les mises à jour aux autres nœuds, qui recalculent alors leurs caches de données dérivées. Nous avons envisagé de migrer ces systèmes pour utiliser un modèle réactif basé sur l'extraction afin de ne pas avoir à nous préoccuper du téléchargement préemptif des nœuds dépendants avant qu'un utilisateur ne modifie une dépendance. Nous voulions que nos utilisateurs bénéficient rapidement de gains en termes de temps de chargement et de mémoire, et cette approche ne nous semblait pas réalisable dans les délais impartis.
Notre approche résolument dynamique
Aucune des deux solutions ne nous permettrait d'améliorer matériellement l'expérience de l'utilisateur à court terme, tout en constituant une solution durable à long terme. La modification et le rechargement différés seraient techniquement plus simples, mais ils ne réduiraient pas la mémoire côté client. La refonte du modèle de données permettrait d'éviter les dépendances en écriture, mais il s'agirait d'une démarche à plus long terme. Par conséquent, nous avons opté pour le calcul des dépendances en écriture, qui permet de trouver un équilibre entre les performances, la faisabilité et l'expérience utilisateur. Avec cette approche de chargement, Figma télécharge la première page et toutes ses dépendances en lecture et en écriture lors du chargement initial. Lorsque l'utilisateur navigue vers d'autres pages, Figma télécharge ces pages (et leurs dépendances en lecture et en écriture) à la demande.
Codage implicite et explicite des dépendances
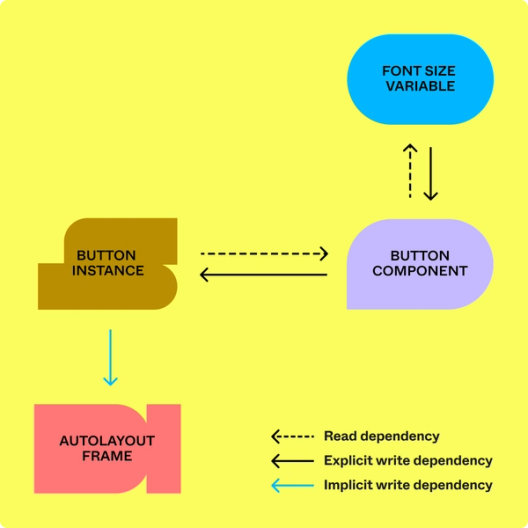
Auparavant, QueryGraph n'encodait que les arêtes de dépendance en lecture puisque les visionneuses et les prototypes n'ont pas besoin de prendre en compte les dépendances en écriture. Pour étendre ce cadre aux éditeurs, nous avons remplacé la structure de données sous-jacente par un graphique bidirectionnel. Lors du chargement dynamique d'un fichier, il était important de pouvoir déterminer rapidement les deux ensembles de dépendances pour un nœud donné.
La dépendance en écriture de la mise en page automatique que nous avons introduite est un exemple de dépendance en écriture implicite entre des nœuds qui ne se réfèrent pas directement l'un à l'autre. Nous avons codé ces dépendances comme un nouveau type d'arête dans notre graphique.
En outre, toutes les dépendances en lecture existantes étaient des dépendances à clé étrangère, ce qui signifie que la dépendance était explicitement encodée dans la structure de données du nœud. Par exemple, les nœuds d'instance possèdent un champ componentID, qui fournit la clé étrangère permettant de rechercher le nœud de composant dont ils dépendent. Le chargement dynamique pour les éditeurs nécessitait d'aller plus loin pour prendre en charge les dépendances en écriture implicites, comme le fait que les modifications apportées à un nœud dans un frame de mise en page automatique peuvent entraîner des modifications automatiques des nœuds avoisinants.
Prise en charge des mises à jour de fichiers en temps réel
Le système multi-utilisateurs conserve en mémoire la représentation complète du fichier et le QueryGraph des dépendances afin d'assurer le chargement et la modification des fichiers par les clients. Pour chaque chargement de fichier dynamique, le client spécifie la page initiale souhaitée et QueryGraph calcule le sous-ensemble du fichier dont le client a besoin. Lorsque les utilisateurs modifient le fichier, le serveur calcule les modifications à envoyer à chaque session en fonction de l'ensemble d'abonnements de la session et de QueryGraph. Par exemple, si un utilisateur n'a chargé que la première page d'un fichier et qu'un collaborateur met à jour le remplissage d'un rectangle sur une autre page, nous n'enverrons pas cette modification au premier utilisateur parce que le rectangle est « inaccessible » à partir de son ensemble d'abonnements.

Lorsque d'autres utilisateurs modifient le fichier, les arêtes de dépendance de QueryGraph peuvent changer. Les modifications apportées au graphique de dépendance par un utilisateur peuvent entraîner un trafic multi-utilisateurs important pour un autre utilisateur. Par exemple, si un utilisateur échange une instance avec un autre composant, le système multi-utilisateurs peut avoir besoin de reconnaître que son collaborateur doit maintenant recevoir le composant et tous ses descendants (et leurs dépendances), même si le premier utilisateur n'a touché à aucun de ces nœuds. Cet utilisateur a simplement rendu ces nœuds nouvellement « accessibles » à son collaborateur, et le système doit réagir en conséquence.
Valider les dépendances
Les actions entreprises par les utilisateurs dans un fichier chargé dynamiquement doivent produire exactement le même ensemble de modifications que si le fichier était entièrement chargé. Pour obtenir la parité de modification, l'ensemble des dépendances en écriture doit être parfait. L'absence d'une dépendance pourrait empêcher un client de mettre à jour des données dérivées sur un nœud en aval. Pour un utilisateur, ces erreurs ressembleraient à des bugs graves : instances divergeant de leur composant d'appui, mise en page incorrecte ou obsolète, ou texte avec des polices manquantes ne s'affichant pas correctement.
Nous voulions savoir si les clients modifiaient strictement les nœuds conformément aux rôles de dépendance en écriture que nous avions énumérés. Pour valider cette hypothèse, nous avons fait fonctionner le système multi-utilisateurs en mode « shadow » pendant une période prolongée. Dans ce mode, le système multi-utilisateurs suit la page sur laquelle se trouve l'utilisateur et calcule les dépendances en écriture comme si elles avaient été chargées dynamiquement, sans modifier le comportement de l'exécution. Si le système multi-utilisateurs recevait des modifications de nœuds en dehors de l'ensemble des dépendances en écriture, il signalait une erreur.
En utilisant ce cadre de validation, nous avons réussi à identifier des dépendances qui nous avaient échappé lors de notre implémentation initiale. Par exemple, nous avons découvert une dépendance en écriture récursive complexe sur l'ensemble des pages, impliquant des contraintes de frames et des instances. Si nous n'avions pas géré cette dépendance correctement, les modifications auraient pu entraîner des calculs de mise en page incomplets. Grâce à notre cadre de validation parallèle, nous avons pu identifier les lacunes, introduire des tests supplémentaires et mettre à jour QueryGraph afin d'éviter des bugs similaires.
La performance en pratique
Avant le chargement dynamique des éditeurs, les clients pouvaient télécharger directement un fichier Figma encodé, sans que notre système multi-utilisateurs ait besoin de le décoder en mémoire. En revanche, avec le chargement dynamique des pages, le serveur doit d'abord décoder le fichier Figma et construire le QueryGraph en mémoire afin de déterminer le contenu à envoyer au client. Ce processus de décodage peut prendre du temps et se trouve sur un tracé décisif, il était donc important de l'optimiser.
Tout d'abord, nous avons veillé à ce que le système multi-utilisateurs puisse commencer le processus de décodage le plus tôt possible. Dès que Figma reçoit la requête GET initiale pour le chargement de la page, notre backend envoie un indice au système multi-utilisateurs indiquant qu'un chargement de fichier est imminent et qu'il doit commencer à précharger le fichier. Ainsi, le système multi-utilisateurs commence à télécharger et à décoder le fichier avant même que le client n'établisse une connexion WebSocket avec celui-ci. Ce type de préchargement permet de réduire de 300 à 500 millisecondes le temps de chargement du percentile 75 (p75).
Ensuite, nous avons introduit le décodage parallèle, une optimisation dans laquelle nous conservons les décalages bruts dans le fichier Figma, ce qui nous permet de diviser le travail de décodage en plusieurs parties que plusieurs cœurs de CPU peuvent traiter simultanément. Le décodage en série du fichier Figma codé en binaire peut être assez lent (plus de cinq secondes pour nos plus gros fichiers !), de sorte qu'en pratique, cette optimisation réduit le temps de décodage de plus de 40 %.
La réduction de la quantité de données que le système multi-utilisateurs envoie aux clients a été une grande victoire pour le chargement dynamique des pages, mais nous avons constaté que nous pouvions aller encore plus loin avec des optimisations supplémentaires côté client. Plus précisément, le client met en cache les descendants des nœuds d'instance en mémoire afin de faciliter la modification et l'interaction par l'utilisateur. Cependant, les « sous-calques » de l'instance sont entièrement dérivables du composant d'appui de l'instance et de toutes les dérogations définies par l'utilisateur, de sorte qu'il n'est pas nécessaire de les matérialiser toutes lors du chargement initial du fichier. Dans le cadre du chargement dynamique des pages, nous différons désormais la matérialisation des sous-calques d'instance pour les nœuds d'autres pages. Cela a permis des gains considérables en termes de temps de chargement, mais a nécessité la mise à jour de dizaines de sous-systèmes afin de supprimer l'hypothèse selon laquelle tous les nœuds sont entièrement matérialisés lors du chargement, et de prendre en charge la matérialisation différée et lente.
Temps de chargement à la baisse
Nous avons proposé le chargement dynamique des pages à des groupes d'utilisateurs pendant six mois, en mesurant soigneusement l'impact de nos changements dans le cadre de tests A/B contrôlés et en surveillant notre télémétrie automatisée. Nous avons finalement obtenu d'excellents résultats :
- 33 % d'accélération pour les chargements de fichiers les plus lents et les plus complexes, malgré des fichiers dont la taille a augmenté de 18 % d'une année sur l'autre
- Réduction de 70 % du nombre de nœuds en mémoire sur le client en ne chargeant que ce dont les utilisateurs ont besoin
- Réduction de 33 % du nombre d'erreurs de mémoire chez les utilisateurs
Nous sommes toujours à la recherche d'opportunités pour optimiser les temps de chargement et réduire la mémoire, et comme les fichiers sont de plus en plus volumineux et complexes, le chargement dynamique des pages est devenu la base de l'amélioration de nos performances. Si ce type de travail vous intéresse, consultez nos offres d'emploi, nous recrutons !
Merci à tous ceux qui ont rendu cela possible, notamment Andrew Chan, Andrew Swan, Darren Tsung, Eddie Shiang, Georgia Rust, Jackie Chui, John Lai, Melissa Kwan et Raghav Anand.