



How we rebuilt the foundations of component instances


By replacing a decade-old architecture with a reactive foundation, we made common operations in large design systems up to 50% faster and unlocked a new way to build dynamic features.
Share How we rebuilt the foundations of component instances
Illustrations by Irene Suosalo
We first introduced components almost ten years ago, just months after Figma's first public release. Components are reusable design elements that stay in sync across the entire project. At its core, the feature is simple: users create a main component, where they define properties like width, height, color, and the overall structure of the asset. Then they can create component instances, which are like smart copies that are updated automatically whenever changes are made to the main component.
The original architecture centered around a runtime called Instance Updater. It was a self-contained system responsible for resolving instance properties, managing their structure, and keeping them in sync with their main components. Other systems, like our layout engines, would delegate to Instance Updater whenever they encountered an instance.
This insulated design made sense in 2016. Instance behavior was relatively simple, and Figma’s runtime was far less complex. But both Figma and our users' ambitions have grown dramatically since then.
Outgrowing our architecture
Over the past decade, we’ve added a huge number of transformative features to Figma, including auto layout (2019), variants (2020), component properties (2022), and variables (2023). Each made design systems more expressive. But they also made component instances dramatically more complex.
In 2025, we looked ahead to roadmap features like slots Slots give you the ability to customize components without breaking the system. We’re sharing five field-tested tips from early users to help you unlock more freedom without giving up control.How to supercharge your design system with slots
In a modern Figma file, an instance might use variants, have variable bindings and apply auto layout. Its children may include nested instances with their own overrides, variable modes, and layout rules. Even small edits can propagate throughout the tree.
To support new features, we kept extending Instance Updater with specialized, bespoke logic. Each integration was a careful dance that was powerful when it worked, but increasingly fragile and slow as responsibilities piled up.
In some files, changing a single variable mode could trigger a cascade of instance updates and layout recalculations across thousands of nodes. In the worst cases, different systems would “fight” over the same subtree, repeatedly invalidating each other. Operations like swapping instances or changing properties would sometimes take seconds, locking up the editor.
As our users built design systems of growing complexity with thousands of components, deep nesting, and complex responsive behavior, we optimized where we could. But the underlying problem remained: A system designed for simple component copies was now responsible for coordinating layout, variables, and reactivity at massive scale.
Choosing radical change
At this point, it became clear that incremental improvements weren't enough. We needed to fundamentally rethink how instances worked.
Our vision was big. First, we wanted proper separation of concerns. Previously, Instance Updater was doing its own auto layout and variable evaluation work for instances. We wanted to remove that complexity, and ensure that layout was handled entirely by layout systems and variable evaluation entirely by variable systems. The instance system would focus solely on what it did best: dynamically resolving which properties and children an instance should have based on its main component.
Second, we wanted granular invalidation. The old system updated entire instances whenever anything changed. In deeply nested components, this meant recursive cascades of work that locked up the editor. We should only be updating parts of the tree that actually changed.
But we didn't want to just fix instances. We recognized that the core capabilities like reactive updates, dependency tracking, and efficient invalidation were features that other teams were increasingly asking for. This insight led to our most ambitious goal: building a generic framework that any developer could leverage to build dynamic features.
Introducing Materializer
To support this new architecture, we built a system we call Materializer. While Instance Updater was specific to component instances, Materializer is a generic system that operates on Figma’s document tree. Materializer’s job is to create and maintain derived subtrees, which are subtrees whose structure and properties are computed from other sources of truth. Besides component instances, there are other examples of features in Figma that can use derived subtrees—one is rich text nodes, which need to stay in sync with source-of-truth content that’s stored in an external CMS.
When building our new architecture, the key insight was separating what to compute from how to keep it up to date. Materializer isn’t responsible for the business logic of what subtree to create—instead, that’s the job of feature code, which defines a blueprint for how a subtree should be derived from the source of truth.
For component instances, the blueprint describes how an instance resolves itself from its main component—what properties it inherits, which overrides apply, and which children should exist. For rich text, the blueprint uses the rich text blocks (like <h1>, <p>, and <img> elements) as the input that tells Materializer to create a corresponding text or image node. Materializer will then track dependencies, invalidate stale data, and re-materialize only what’s necessary.
Once we could describe how subtrees should be derived, the next challenge was ensuring that Materializer kept them up to date as their inputs changed. There can be many independent changes that impact derived trees, and we need to avoid doing unnecessary work across the document every time we make an update.
We considered two approaches for reactivity:
- With pull-based invalidation, we check whether a node is stale when reading that node, similar to React. This avoids maintaining an explicit dependency graph, but it breaks down in a system like Figma’s. Due to cross-tree references and deeply nested dependencies, determining whether anything relevant changed often requires reconstructing large portions of the dependency chain on every read.
- With push-based invalidation, we maintain an explicit dependency graph. When a source changes, we mark its dependents as dirty and recompute them later. This requires more bookkeeping up front, but it gives us precise control over what needs to update, and just as importantly, what doesn’t.
We chose push-based invalidation, with one key refinement: Dependency tracking is automatic. As nodes read data during materialization, Materializer records those relationships implicitly. Developers don’t declare dependencies by hand; the system learns them as it runs.
Coordinating runtime systems
Building Materializer was only half the challenge. It gave us granular invalidation and a generic framework for deriving subtrees from blueprints. But Materializer didn’t operate in isolation.
Over time, Figma’s client has grown into a set of powerful runtime systems, including layout engines, variable resolvers, and constraint enforcers that all respond to changes in the document. Each had evolved independently, with its own logic for when and how updates should run.
Coordinating Materializer with these systems—while preserving clear separation of concerns—required a second step: introducing a shared runtime orchestration layer. Before this work, each runtime system managed its own updates and scheduled itself in ad hoc ways, which made side effects hard to reason about.
As we unified these runtimes under a common framework, we gained something just as valuable as efficiency: visibility. Running updates in a predictable order surfaced hidden feedback loops, where later systems would invalidate work done by earlier ones and force them to re-run. We call these patterns “back-dirties.” Making them explicit helped us eliminate many of them and move closer to a more unidirectional flow, where source-of-truth changes trigger all relevant side effects across our various systems in a predictable way.

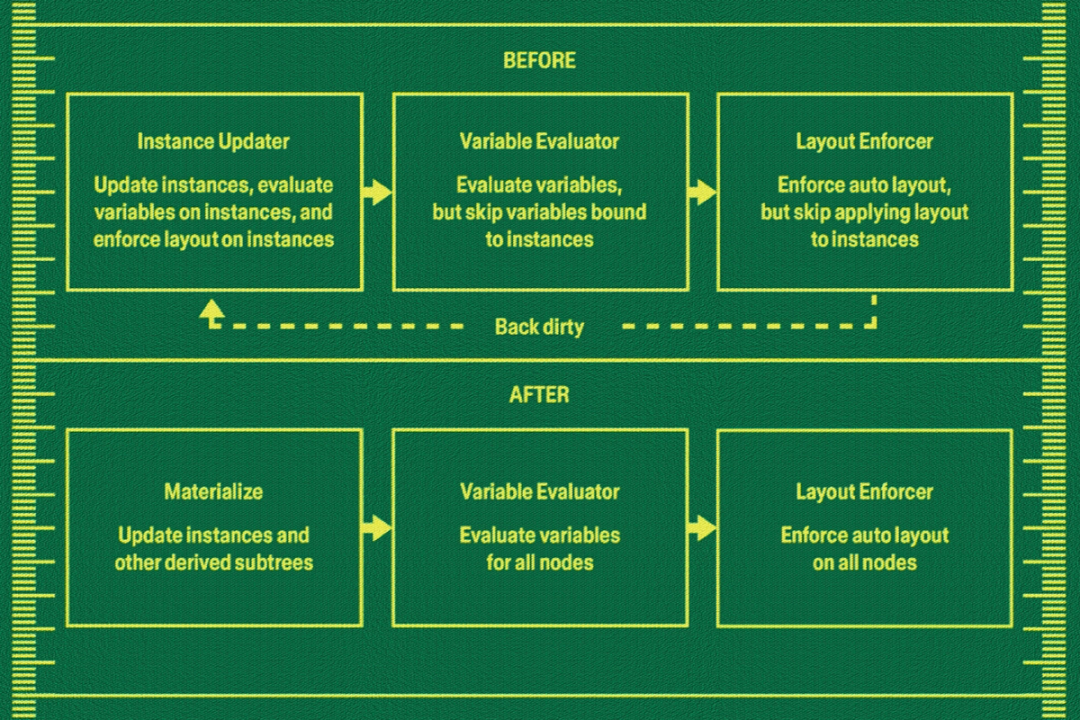
The result was a cleaner separation of responsibilities. Layout logic lives in layout systems. Variable logic lives in variable systems. Instance resolution no longer tries to coordinate everything itself. Product teams can now own their features vertically, building on shared infrastructure instead of re-solving the same orchestration problems.
Rolling out to millions of users
Rewriting instance resolution touched one of the most heavily used parts of Figma. Even small behavioral differences could disrupt critical workflows across millions of files.
While it was conceptually straightforward, porting instance resolution from a self-contained system into a shared runtime introduced subtle differences in execution order and behavior. Many of these differences weren’t obvious and only surfaced in edge cases that weren’t yet covered by unit tests.
To manage that risk, we relied on extensive side-by-side validation. For months, we ran the old and new runtimes in parallel across hundreds of thousands of real production files, comparing both data models and rendered output to ensure designs looked and behaved identically.
Using the same validation process, we also collected metrics on performance and reasoned through performance tradeoffs. Supporting automatic reactivity required additional dependency caches, which improved interactive performance but carried potential costs in file load time and memory usage. By tracking these metrics alongside correctness, we were able to identify regressions early and land targeted optimizations before rollout.
Only once the systems matched across correctness and performance did we begin gradually shipping the new architecture to production. This discipline allowed us to ship a foundational rewrite while preserving the stability users rely on.
Returns on a new foundation
With the new architecture in place, the impact was immediate.
Faster, more predictable performance
In large design system files, common operations like swapping instances and editing nested components became significantly faster. By avoiding unnecessary reprocessing of entire instance subtrees, the new system reduced cascading work that had previously made these interactions feel sluggish.
In internal benchmarks, one of the most expensive cases—variable mode changes—improved by 40–50% in large files, which was representative of the broader gains we saw across common instance edits.
Clearer boundaries, fewer bugs
Separating instance resolution from layout and variable evaluation eliminated entire classes of subtle bugs. Systems no longer “fight” over the same subtree, and feedback loops that once caused oscillations are now easier to detect or avoid entirely. Clear ownership—layout in layout systems, variables in variable systems, instance resolution focused on materialization—makes behavior easier to reason about and safer to evolve.
Unlocking new features
Perhaps the biggest return was developer velocity. Without this framework, adding new kinds of dynamic content would have meant reimplementing reactivity and invalidation from scratch. Rich text was the first net-new feature built directly on this new foundation, and slots was built by composing on top of the new architecture rather than introducing another bespoke system. Other teams across Figma’s products are already building on the Materializer framework to ship new kinds of dynamic content.
At Figma, we believe in sweating the details of our craft. This project embodied that philosophy: taking the time to deeply understand our problem space, design elegant abstractions, and execute with precision. The result is not just faster instances, but a foundation that will accelerate how we build for years to come.

We're hiring engineers! Learn more about life at Figma, and browse our open roles.
This year-long journey involved over 15 contributors: Aaron Kau, Brian Lam, Connor Skees, Dennis Jeong, Edward Im, Georgia Rust, Isaac Goldberg, Jason Yoon, Jeff Lee, Jenning Chen, John Lai, Josh Shi, Melissa Kwan, Mike Johnston, Olympia Walker, Peter Hayes, and Stephanie Cheuk. Huge thanks to this incredible team and the many others who supported this effort.
Naomi is a software engineer on Figma’s editor team. She has worked on core design systems features including Variants and Component Properties, and is currently focused on improving performance and building internal frameworks to increase developer velocity.



