



Dateiladezeiten Seite für Seite beschleunigen





Figma-Dateien sind oft groß und komplex und enthalten lange Seiten, Bibliotheken, lokale Komponenten und Prototypen-Bildschirme. Hier beschreiben wir, wie das dynamische Laden von Seiten die höchsten Ladezeiten um 33 % beschleunigen konnte.
Dateiladezeiten Seite für Seite beschleunigen teilen
Illustrationen von María Medem
Bei den langsamsten 5 % der Seitenladevorgänge konnten wir eine Reduzierung der Ladezeiten um 33 % erzielen.
Jedes Technikteam möchte, dass sich das eigene Produkt möglichst schnell anfühlt. Das Benutzererlebnis muss optimal gestaltet sein, aber auch Ladegeschwindigkeiten prägen den ersten Eindruck maßgebend. Auf uns trifft das besonders zu. Einige Nutzer*innen verbringen ganze Arbeitstage in Figma, und feine Perfomance-Verbesserungen, mit denen Einsparungen im Sekundenbereich erzielt werden, summieren sich über den Verlauf eines Tages. Während unsere Produktteams bei Figma neue Funktionen entwickeln und unsere Nutzer*innen immer mehr Inhalte in ihren Dateien unterbringen, arbeiten unsere Plattformteams daran, mitzuhalten und die Performance zu optimieren. Der ideale Trend für Ladezeiten sollte sich auf den Diagrammen nach unten rechts bewegen: Unser Ziel ist es, die Dateiladezeiten stetig zu senken, während die Dateigrößen mit der Zeit steigen.
Die Performance sollte der Komplexität entsprechen, die von Nutzer*innen wahrgenommenen wird. Wenn Nutzer*innen eine Seite mit nur wenigen Frames laden, sollte Figma die Arbeitsfläche annähernd sofort anzeigen, selbst wenn die Datei noch Dutzende andere Seiten mit jeweils Hunderten Frames enthält. Durch die Analyse von Nutzungsmustern haben wir herausgefunden, dass viele Nutzer*innen Dateien als Projekte behandeln, also alle Aspekte eines Arbeitsablaufs in einer einzigen Datei integrieren. Dies bedingt, dass viele Nutzer*innen im Rahmen einer einzelnen Session nicht auf alle Seiten navigieren. Uns wurde klar, dass wir dadurch die Ladezeiten bedeutend verbessern und die Speichernutzung reduzieren konnten, indem wir Inhalte bedarfsorientiert laden, anstatt den gesamten Inhalt auf einmal bereitzustellen.
Leseabhängigkeiten in unserem Datenmodell
Dynamisches Laden zu Zwecken der Performance-Optimierung ist als Konzept nichts Neues. Jedoch bestanden durch die Struktur der browserbasierten Dateien von Figma einige Herausforderungen, die wir überwinden mussten. Allgemein gefasst ist die Figma-Datei eine Struktur von Knoten, wobei jeder Knoten eine interaktionsfähige Ebene mit eigenen Eigenschaften darstellt. Von Bedeutung ist hierbei, dass bestimmte Knoten sich auf weitere Knoten auf anderen Seiten beziehen. Dadurch können zwischen Knoten mehrere seitenübergreifende Abhängigkeiten entstehen, sowohl einfacher strukturierte als auch komplexere, die wir berücksichtigen mussten.
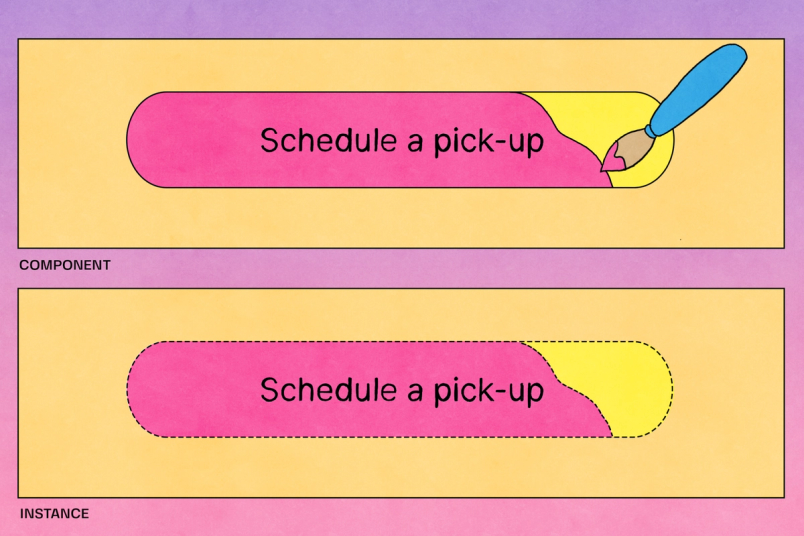
Beim Datenmodell von Figma beinhalten Instanzen einen Pointer auf einen weiteren Knoten, die Backing-Komponente der Instanz, die sich auf einer anderen Seite befinden kann. Dies bezeichnen wir als Leseabhängigkeit, wobei sich die Leseabhängigkeit der Instanz auf die Komponente bezieht. Um die Instanz korrekt zu rendern, muss der Client zunächst den Knoten der Komponente herunterladen.
Komponenten sind Elemente, die sich in gesamten Designs wiederverwenden lassen. Dank ihnen lassen sich konsistente Designs über Projekte hinweg erstellen und verwalten. Eine Instanz ist eine verlinkte Kopie der Komponente, die automatisch alle Aktualisierungen empfängt, die an der Komponente vorgenommen werden.
Neben Komponenten und Instanzen sind an vielen Funktionen von Figma auch Leseabhängigkeiten beteiligt. Figma implementiert z. B. Stile als Knoten, die für Nutzer*innen unsichtbar sind. Wenn ein Frame den Füllungsstil „BrandPrimary“ #FFD966 verwendet, muss der Client zunächst den entsprechenden Knoten für den Stil herunterladen. Bei Variablen verhält es sich ähnlich. Wenn ein Knoten die Größenvariable „Text-Unterüberschrift“ auf seine Schriftgröße anwendet, fordert der Client Zugriff auf den Knoten der Variable an, um den richtigen Rohwert (z. B. 16) für die Schriftgröße aufzulösen.
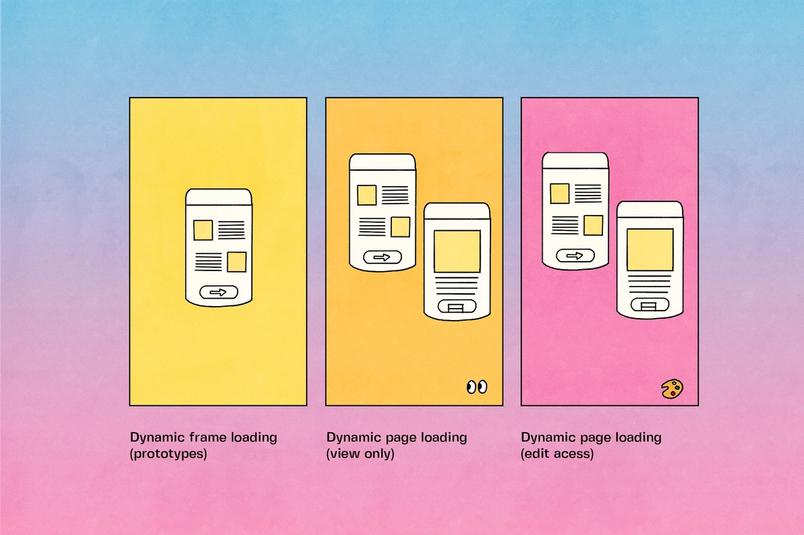
Dynamisches Laden als Grundlage für Lesevorgänge
Mit Hilfe früherer Versionen von dynamischem Laden konnten wir diese Herausforderungen im Fall von Dateien mit Lesezugriff und Prototypen überwinden. Wir haben ein Abhängigkeiten-Framework namens QueryGraph erstellt, das im Speicher als ein Diagramm von Edges zwischen abhängigen Knoten repräsentiert ist. Dies ist die Komponente der Multiplayer-Technologie von Figma, die ermittelt, welcher Teil einer Datei an die verbundenen Clients zu senden ist. QueryGraph und sein Diagramm von Leseabhängigkeiten bildeten die Grundlage für ein schnelleres Laden von Dateien und Prototypen für Nutzer*innen mit Lesezugriff. In jedem Fall war das dynamische Laden auf die Art des Inhalts bezogen, der anfänglich beim Laden einer Datei gerendert wird:
- Seiten auf der Figma-Arbeitsfläche: Anstatt die gesamte Datei zu laden, beginnt Figma mit dem ausschließlichen Laden der ausgewählten Seite und lädt zusätzliche Seiten bedarfsorientiert. Mithilfe von QueryGraph sendet das Multiplayer-System von Figma die angeforderte Seite zusammen mit etwaigen Leseabhängigkeiten auf andere Seiten an den Client.
- Frames in Prototypen: Für das Anzeigen von Prototypen lädt Figma einzelne Frames dynamisch, wobei stets nur ein Bildschirm angezeigt wird. Figma lädt zudem Frames vor, die über eine festgelegte Anzahl von Übergängen vom aktuellen Zustand aus erreicht werden können, um merkliche Verzögerungen zu verhindern. Auch hierbei versorgt QueryGraph den Client mit allen erforderlichen Teilen der Figma-Datei, ohne unnötige Elemente zu laden.
Zwar konnten Nutzer*innen mit Lesezugriff vom dynamischen Laden der Seiten profitieren, jedoch stammen 70 % unserer täglichen Dateiladevorgänge von editierbaren Dateien. Unser Erfolg stützte sich auf das dynamische Laden von Prototypen in Form einzelner Frames und das seitenweise Laden von Dateien mit Lesezugriff. Genau diese Ladelogik wollten wir auch auf editierbare Dateien anwenden. Die Herausforderung bestand darin, dafür zu sorgen, dass Änderungen über ungeladene Inhalte hinweg korrekt bereitgestellt werden, wenn eine Änderung sich auf Komponenten auf Seiten bezieht, die noch nicht geladen sind. Um diese Optimierung für alle verfügbar zu machen, konnten wir nicht einfach die vorhandene Logik von Clients mit Lesezugriff wiederverwenden. Damit auch Nutzer*innen mit Schreibzugriff von dynamischem Laden profitieren konnten, mussten wir unser System zur Nachverfolgung von Abhängigkeiten so erweitern, dass eine neue Art von Edge unterstützt wird.

Schreibabhängigkeiten aufräumen
Während für das Anzeigen und Rendern der Bestandteile von Figma-Dateien Leseabhängigkeiten erforderlich sind, werden für das Bearbeiten von Dateibestandteilen Schreibabhängigkeiten benötigt. In vielen Fällen entspricht eine Schreibabhängigkeit der Umkehrung einer vorhandenen Leseabhängigkeit. Das liegt daran, dass Figma die Ergebnisse aufwändiger Berechnungen, etwa des Algorithmus für das Textlayout, in den Cache lädt. Wenn der Stil geändert wird, führt Figma den Algorithmus für das Textlayout erneut aus und lädt die davon abgeleiteten Datenergebnisse in den Cache, damit sie stets für das Rendern bereitstehen. Wenn z. B. ein Textstil die Schriftart einer Textebene festlegt, ist dies eine Abhängigkeit der Textebene auf den Knoten des Textstils. Die Umkehrung davon ergibt eine Schreibabhängigkeit: Der Knoten des Stils hat eine Schreibabhängigkeit auf die Textebene. Damit der Stilknoten also sicher bearbeitet werden kann, benötigt Figma die untergeordnete Textebene.
Das ist erforderlich, um dynamisches Laden für Schreibvorgänge zu unterstützen. Wenn Nutzer*innen einen Teil einer Figma-Datei bearbeiten, z. B. durch Ändern des Textstils, muss der Client auf alle zu aktualisierenden untergeordneten Objekte zugreifen können, etwa die im Cache befindliche Glyphen-Informationen einer Textebene.
Hier einige Beispiele für Schreibabhängigkeiten im Figma-Datenmodell:
- Komponenten haben Schreibabhängigkeiten auf alle ihre Instanzen, die sich auf anderen Seiten befinden können. Wenn Nutzer*innen eine Komponente bearbeiten, muss Figma die Caches auf den Instanzen der Komponente vorbereiten und aktualisieren. Dieser Zusammenhang trifft auch auf Textstile und Variablen zu.
- Wenn bei der Verwendung von Auto-Layout die Größe oder Position eines Knotens verändert wird, kann sich auch die Größe und Position eines anderen Knotens ändern. Dies ist somit auch eine Schreibabhängigkeit. Bei Komponenten und Instanzen kann eine derartige Auto-Layout-Schreibabhängigkeit seitenübergreifend bestehen. (Beispielsweise kann die Bearbeitung einer Komponente auf einer Seite dazu führen, dass die Größe einer Instanz auf einer anderen Seite geändert wird, was wiederum darin resultieren kann, dass Schwesterinstanzen in einem Auto-Layout-Frame neu angeordnet werden.)

Verschiedene Ansätze
Als wir die verschiedenen Ansätze diskutierten, um dynamisches Laden auch für Schreibvorgänge bereitzustellen, hat sich ein Favorit ergeben: das Berechnen von Schreibabhängigkeiten. Dies würde erfordern, das Multiplayer-System von Figma für die Berücksichtigung von Schreibabhängigkeiten zu überarbeiten. Das verhält sich zwar analog zu unserer Vorgehensweise für Nutzer*innen mit Lesezugriff und entsprechenden Leseabhängigkeiten, jedoch ist das Unterfangen im Fall von Lesezugriffen deutlich weniger riskant. Wenn sich bei der Ladelogik ein Fehler ergibt, wird bei Nutzer*innen mit Lesezugriff eine Datei möglicherweise fehlerhaft angezeigt, jedoch steht die Integrität der Datei nicht auf dem Spiel. Bei Anwendungsbereichen mit Schreibvorgängen besteht dagegen das Risiko von Schäden an Dateien, wenn die Ladelogik nicht die richtigen Abhängigkeiten enthält und dadurch Dateninkonsistenzen auftreten. (Was, wenn du eine Änderung vornimmst, und diese auf anderen Seiten nicht berücksichtigt wird?) Da das Definieren von Schreibabhängigkeiten komplex ausfällt, haben wir auch zwei alternative, einfachere Lösungen in Erwägung gezogen: Das Zurückstellen von Änderungen und Vorladen sowie das Überarbeiten des Datenmodells.
Zurückstellen von Änderungen und Vorladen
Bei diesem Ansatz würde die erste Seite mit derselben Logik geladen, die wir beim dynamischen Laden für Nutzer*innen mit Lesezugriff verwenden. Sobald die erste Seite lädt, könnten Nutzer*innen die Seite verschieben, vergrößern und die Seiteninhalte ansehen. Im Hintergrund würde Figma den Rest der Datei laden, wie es sich auch derzeit gestaltet. Der Unterschied bestünde darin, die Datei mit Lesezugriff zu öffnen, bis der Rest der Datei geladen ist. Dadurch würde sich möglicherweise eine Verzögerung ergeben, bis Nutzer*innen eine Änderung vornehmen können. Zudem könnte dieses Konzept eine komplexe Ladelogik erfordern: Wir müssten die Seitenladevorgänge im Hintergrund fortsetzen und gleichzeitig in der Lage sein, eine Seite an vorderste Stelle der Ladewarteschleife zu verschieben, wenn Nutzer*innen auf diese Seite wechseln möchten. Es könnte schwierig werden, derart große Datenmengen vorzuladen, ohne dass es bei Nutzer*innen zu Frame Hitching oder Verzögerungen kommt.
Überarbeiten des Datenmodells
Schreibabhängigkeiten repräsentieren abgeleitete Daten. Wenn Nutzer*innen eine Abhängigkeit bearbeiten, werden die Aktualisierungen bei unserem derzeitigen System über einen push-basierten Mechanismus auf andere Knoten angewendet, die daraufhin ihre abgeleiteten Daten-Caches neu berechnen. Wir haben in Erwägung gezogen, diese Systeme auf ein pull-basiertes reaktives Modell umzustellen, damit kein vorgeschaltetes Herunterladen abhängiger Knoten erforderlich ist, bevor Nutzer*innen eine Abhängigkeit bearbeiten. Unsere Systeme entsprechend umzustellen, wäre jedoch ein äußerst umfangreiches Vorhaben. Wir wollten die Verbesserungen bei Ladezeiten und Speicherprofil möglichst schnell für unsere Nutzer*innen bereitstellen, und dieser Ansatz passte nicht in unseren Zeitplan.
Unser dynamisches Konzept
Keine der Alternativen eignete sich, um das Benutzererlebnis kurzfristig bedeutend zu verbessern und langfristig eine nachhaltige Lösung zu etablieren. Das Zurückstellen von Änderungen und Vorladen wäre als Konzept technisch einfacher umzusetzen, würde jedoch die clientseitige Speichernutzung nicht optimieren. Das Überarbeiten des Datenmodells könnte zwar die Notwendigkeit von Schreibabhängigkeiten vermeiden, wäre aber ein längerfristiges Projekt. Letztendlich haben wir uns für die Berechnung von Schreibabhängigkeiten entschieden, um Performance, Machbarkeit und Benutzerfreundlichkeit auf einen Nenner zu bringen. Bei diesem Ladekonzept lädt Figma die erste Seite mitsamt all ihren Lese- und Schreibabhängigkeiten herunter. Wenn Nutzer*innen zu anderen Seiten navigieren, lädt Figma die entsprechenden Seiten (und ihre Lese- und Schreibabhängigkeiten) bedarfsorientiert herunter.
Abhängigkeiten implizit und explizit kodieren
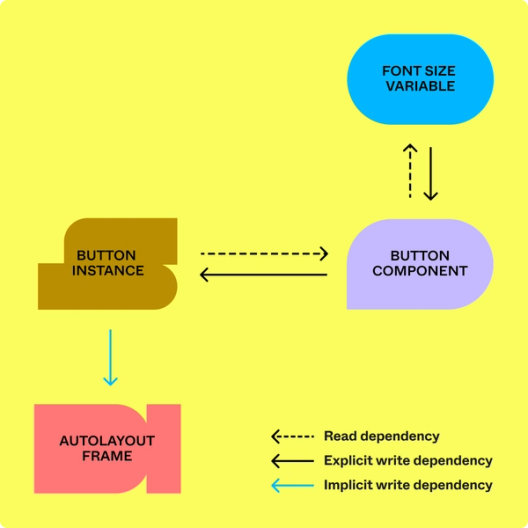
Bisher kodierte QueryGraph nur Edges von Leseabhängigkeiten, da Schreibabhängigkeiten für Lesevorgänge und Prototypen irrelevant sind. Um dieses Framework auf Schreibvorgänge zu erweitern, haben wir die zugrundeliegende Datenstruktur durch ein bidirektionales Konzept ersetzt. Es war wichtig, während des dynamischen Ladens einer Datei die Abhängigkeiten beider Typen schnell für einen gegebenen Knoten erfassen zu können.
Die Auto-Layout-Schreibabhängigkeit, die wir eingeführt haben, stellt ein Beispiel einer impliziten Schreibabhängigkeit zwischen Knoten dar, die anderenfalls nicht direkt aufeinander verweisen. Diese Abhängigkeiten kodierten wir in unserem Graph als neuen Edge-Typ.
Zudem gehörten alle vorhandenen Leseabhängigkeiten zu den Foreign‑Key-Abhängigkeiten, bei denen die Abhängigkeit explizit in der Datenstruktur der Knoten kodiert ist. Z. B. verfügen Instanzknoten über das Feld componentID, das den Foreign Key bereitstellt, der den Komponentenknoten angibt, von dem der Instanzknoten abhängt. Um dynamisches Laden für Schreibvorgänge bereitzustellen, mussten wir das System zur Unterstützung impliziter Schreibabhängigkeiten erweitern. Wenn etwa Änderungen an einem Knoten in einem Frame mit Auto-Layout vorgenommen werden, kann dies zu automatischen Änderungen an benachbarten Knoten führen.
Unterstützung von Dateiaktualisierungen in Echtzeit
In Multiplayer ist sowohl die vollständige Repräsentation der Datei als auch der QueryGraph der Abhängigkeiten im Speicher enthalten, um das clientseitige Laden und Bearbeiten von Dateien zu gewährleisten. Bei jedem dynamischen Dateiladevorgang gibt der Client die angefragte anfängliche Seite an, und QueryGraph berechnet die Anteile der Datei, die vom Client benötigt werden. Während Nutzer*innen die Datei bearbeiten, berechnet der Server, welche Änderungen an eine Session gesendet werden müssen. Dies wird als Funktion der Abonnements und des QueryGraph der entsprechenden Session ermittelt. Wenn z. B. ein*e Nutzer*in nur die erste Seite einer Datei lädt und eine mitarbeitende Person auf einer anderen Seite die Füllung eines Rechtecks ändert, würden wir diese Änderung nicht an die ersten Nutzer*innen senden, da das Rechteck über deren abonnierten Datensatz „nicht erreichbar“ ist.

Während andere Nutzer*innen die Datei bearbeiten, können sich die abhängigen Edges des QueryGraph ändern. Änderungen am Abhängigkeiten-Graph durch Nutzer*innen können zu erheblichem Multiplayer-Datenverkehr für andere Nutzer*innen führen. Wenn ein*e Nutzer*in eine Instanz auf eine andere Komponente wechselt, muss Multiplayer möglicherweise registrieren, dass daraufhin auch eine mitarbeitende Person die Komponente (und deren Abhängigkeiten) erhalten muss, selbst wenn die/der erste Nutzer*in mit keinem dieser Knoten interagiert hat. Diese*r Nutzer*in hat die entsprechenden Knoten für die mitarbeitende Person wieder „erreichbar“ gemacht, und das System muss dementsprechend reagieren.
Abhängigkeiten validieren
Aktionen, die von Nutzer*innen in einer dynamisch geladenen Datei durchgeführt werden, sollten exakt die gleiche Teilmenge an Änderungen hervorbringen, die auch für eine vollständig geladene Seite generiert würden. Um beim Bearbeiten Konsistenz zu gewährleisten, mussten die Schreibabhängigkeiten perfekt definiert sein. Eine fehlende Abhängigkeit konnte dazu führen, dass ein Client die abgeleiteten Daten auf einem untergeordneten Knoten nicht aktualisiert. Derartige Fehler würden für Nutzer*innen schwerwiegend ausfallen: Instanzen, die von ihrer Backing-Komponente abweichen, fehlerhafte Layouts oder Text mit fehlerhaft dargestellten Schriftarten.
Wir wollten sicherstellen, dass Knoten nur genau entsprechend den Schreibabhängigkeitsrollen, die wir festgelegt hatten, von Clients bearbeitet werden. Um dies zu validieren, führten wir Multiplayer in einem Shadow-Modus aus. In diesem Modus erfasste das Multiplayer-System, auf welcher Seite sich Nutzer*innen befinden, um Schreibabhängigkeiten zu berechnen, als würden diese dynamisch geladen, ohne dabei Änderungen an Laufzeitverhalten vorzunehmen. Wenn Multiplayer Änderungsanfragen für Knoten außerhalb der Schreibabhängigkeiten erhielt, meldete es einen Fehler.
Mit diesem Validierungsframework konnten wir Abhängigkeiten aufdecken, die wir bei unserer ursprünglichen Implementierung übersehen hatten. Dadurch haben wir z. B. eine komplexe, seitenübergreifende rekursive Schreibabhängigkeit mit Beteiligung von Frame-Einschränkungen und Instanzen entdeckt. Wenn wir mit dieser Abhängigkeit nicht richtig umgegangen wären, hätten Änderungen zu unvollständigen Layoutberechnungen führen können. Mit unserem Shadow-Validierungsframework konnten wir Lücken auffinden, zusätzliche Tests durchführen und QueryGraph aktualisieren, um ähnliche Fehler zu verhindern.
Performance in der Praxis
Vor der Einführung des dynamischen Ladens mit Schreibzugriff, konnten kodierte Figma-Dateien direkt über Clients herunterladen werden, ohne dass unser Multiplayer-System sie im Speicher dekodieren musste. Für das dynamische Laden von Seiten muss der Server aber zunächst die Figma-Datei und QueryGraph im Speicher dekodieren, um zu bestimmen, welche Inhalte an den Client gesendet werden müssen. Dieser Dekodierungsvorgang kann zeitaufwändig ausfallen. Da er sich im kritischen Pfad befindet, war seine Optimierung sehr wichtig.
Zunächst stellten wir sicher, dass Multiplayer schnellstmöglich mit dem Dekodierungsvorgang beginnen kann. Sobald Figma die anfängliche GET-Anfrage zum Laden der Seite erhält, sendet unser Backend einen Hinweis an Multiplayer, der angibt, dass ein Dateiladevorgang unmittelbar bevorsteht, und dass die Datei vorgeladen werden muss. Dadurch kann Multiplayer mit dem Herunterladen und Dekodieren der Datei beginnen, noch bevor der Client eine WebSocket-Verbindung zu Multiplayer herstellt. Diese Art des Vorladens reduziert das 75. Perzentil (p75) der Ladezeiten um 300 bis 500 Millisekunden.
Als Nächstes haben wir paralleles Dekodieren eingeführt, eine Optimierung, bei der wir rohe Offsets persistent in die Figma-Datei einbringen, wodurch wir Dekodierungs-Workloads in Chunks aufteilen können, die sich von mehreren CPU-Kernen gleichzeitig verarbeiten lassen. Das serielle Kodieren der Figma-Datei kann recht zeitaufwändig sein (über 5 Sekunden bei unseren größten Dateien). In der Praxis reduziert diese Methode die Dekodierungszeit also um über 40 %.
Das Reduzieren der Datenmenge, die durch das Multiplayer-System an Clients gesendet wird, hat sich äußerst positiv auf das dynamische Laden von Seiten ausgewirkt. Wir haben aber auch Potenzial erkannt, um bei der clientseitigen Optimierung noch weiter zu gehen. Der Client lädt Abkömmlinge von Instanzknoten als Cache in den Speicher, um Nutzer*innen das Bearbeiten und Interagieren zu erleichtern. Jedoch lassen sich „Sublayer“ von Instanzen vollständig von der Backing-Komponente der Instanz und von durch Nutzer*innen definierte Overrides ableiten. Es ist also nicht erforderlich, alle Sublayer beim anfänglichen Laden der Datei zu materialisieren. Als Teil des dynamischen Ladens von Seiten stellen wir jetzt das Materialisieren der Sublayer von Instanzen für Knoten auf anderen Seiten zurück. Das hat zu enormen Einsparungen bei den Ladezeiten geführt. Dafür mussten Dutzende Subsysteme überarbeitet werden, um die Annahme zu entfernen, dass alle Knoten beim Laden vollständig materialisiert werden müssen, und um eine zurückgestellte Materialisierung zu unterstützen.
Ladezeiten nach unten rechts verschieben
Das dynamische Laden von Seiten stellten wir über einen Zeitraum von 6 Monaten für einzelne Gruppen von Nutzer*innen bereit. Dabei haben wir die Auswirkungen unserer Aktualisierungen durch kontrollierte A/B-Tests und das Überwachen unserer automatisierten Telemetrie gemessen. Nach Abschluss konnten wir eine gute Bilanz ziehen:
- Beschleunigung von 33 % der langsamsten und komplexesten Dateiladevorgänge, trotz einem jährlichen Wachstum der Dateigröße um 18 %
- Reduzierung der clientseitigen Anzahl an Knoten im Speicher um 70 %, indem nur geladen wird, was Nutzer*innen benötigen
- 33 % weniger Nutzer*innen erhalten Fehler bezüglich geringer Speicherverfügbarkeit
Wir suchen ständig nach Möglichkeiten, um Ladezeiten zu optimieren und den Speicherbedarf zu reduzieren. Angesichts zunehmend großer und komplexer Dateien ist das dynamische Laden von Seiten zur Grundlage unserer Performance-Verbesserungen geworden. Wenn du dich für derartige Tätigkeiten interessierst, schau dir gerne unsere offenen Stellen an. Wir suchen neue Mitarbeiter*innen.
Vielen Dank an alle Mitwirkenden, darunter Andrew Chan, Andrew Swan, Darren Tsung, Eddie Shiang, Georgia Rust, Jackie Chui, John Lai, Melissa Kwan und Raghav Anand.

