



ファイルの読み込みを1ページずつスピードアップ





Figmaファイルは無数のページ、ライブラリとローカルコンポーネント、プロトタイプ画面で構成されており、大きくて複雑であることがよくあります。動的ページ読み込みにより、最も遅い読み込み時間が33%改善された方法をご紹介します。
ファイルの読み込みを1ページずつスピードアップを共有
María Medemによるイラスト
ページ読み込みの最も遅い5%で、読み込み時間が33%減少しました。
どのエンジニアリングチームも、チームの製品が高速で動作すると感じられることを望んでいます。ユーザーに可能な限り最高の体験を提供する以上に、読み込みの速さが根本的にユーザーの第一印象を形作ります。このことは、Figmaにとって特に当てはまります。ユーザーは1日中Figmaを使用することが多いため、数秒を節約するような段階的なパフォーマンスの改善が、1日を通して累積されていきます。Figmaのプロダクトチームがより多くの機能を構築し、ユーザーがファイルにより多くのコンテンツを追加するなか、プラットフォームチームはパフォーマンスの維持と向上に努めています。読み込み時間が右下がりの傾向を示せば理想的です。つまり、ファイルのサイズが大きくなっても、ファイルの読み込み時間が、長期的に短くなっていくことを望んでいます。
パフォーマンスは、ユーザーが感じる複雑さに対応するはずです。ユーザーが数フレームしかないページを読み込んだ場合、ファイルにそれぞれ数百フレームを含む他のページが数十ページあったとしても、Figmaはそのキャンバスをほとんど即座に表示できなければなりません。使用パターンを調べることで、多くのユーザーがファイルをプロジェクトとして扱っていること、つまり、1つのファイルにワークストリームのあらゆる側面を格納しているため、ほとんどのユーザーは1回のセッション内で移動しないページがあることさえ普通でした。すべてのコンテンツを一度に読み込むのではなく、必要に応じてコンテンツを動的に読み込むことで、読み込み時間を大幅に改善し、メモリーを削減できることに気づきました。
データモデルにおける読み取り依存関係の理解
パフォーマンスの最適化に対する動的読み込みは新しいコンセプトではありませんが、Figmaのブラウザベースのファイル構造に特有のいくつかの課題があり、それを解決する必要がありました。大まかに言えば、Figmaファイルはノードのツリーであり、各ノードはプロパティを持つインタラクティブなレイヤーです。重要なのは、特定のノードが、他のページ上のノードを参照できることです。つまり、ノード間には、より明白なものから非常に複雑なものまで、多くのページ間依存関係が存在する可能性があり、それを考慮する必要がありました。
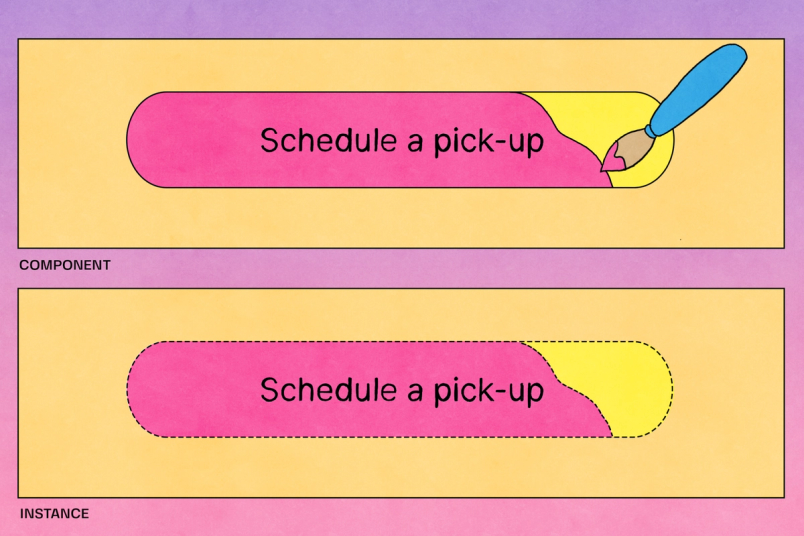
Figmaのデータモデルでは、インスタンスは別のノードへのポインターを含んでいます。このノードはインスタンスのバッキングコンポーネントで、別のページに存在する可能性があります。このエッジを読み取り依存関係と呼びます。ここでは、インスタンスはコンポーネントに対して読み取り依存関係を持ちます。インスタンスを正しくレンダリングするには、クライアントはまずコンポーネントのノードをダウンロードする必要があります。
コンポーネントは、デザイン全体で再利用できる要素です。プロジェクト間で一貫性のあるデザインを作成、管理するのに役立ちます。インスタンスはコンポーネントのリンクされたコピーであり、コンポーネントに加えられたあらゆる更新を自動的に受け取ります。
コンポーネントやインスタンスに加え、Figmaの多くの機能には、読み取り依存関係があります。たとえば、Figmaは、スタイルをユーザーから見えないノードとして実装しています。フレームが「BrandPrimary」の塗りスタイル#FFD966を使用している場合、フレームをレンダリングするには、クライアントはまず、対応するスタイルノードをダウンロードする必要があります。バリアブルも同様です。ノードがフォントサイズに「text-subheader」サイズバリアブルを適用する場合、クライアントは、フォントサイズの正しいローバリュー(16など)を解決するために、バリアブルノードにアクセスする必要があります。
閲覧者向けの動的読み込みの構築
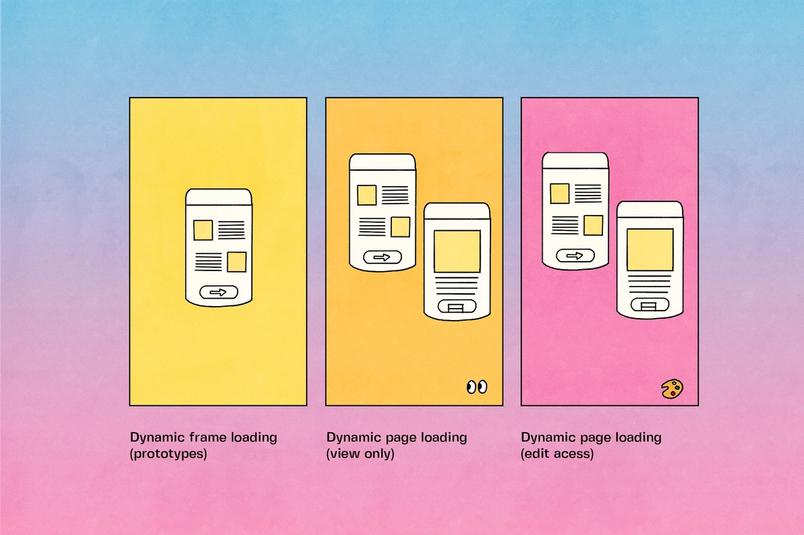
過去に繰り返し実施した表示専用のファイルやプロトタイプに対する動的読み込みを踏まえて、これらの課題を解決することができました。私たちは、QueryGraphと呼ばれる依存関係フレームワークを作成しました。QueryGraphは、依存ノード間のエッジのインメモリーグラフとして表され、接続されたクライアントに送信するファイルの部分を追跡するFigmaのマルチプレイヤーテクノロジーのコンポーネントです。QueryGraphと、その読み取り依存関係のグラフは、表示専用ユーザーにとってファイルやプロトタイプの読み込みを高速化するための基礎となりました。それぞれの場合において、動的読み込みの単位は、最初のファイル読み込み時にレンダリングするコンテンツのタイプに対応しています。
- Figmaキャンバスのページ単位: ファイル全体を読み込むのではなく、Figmaは、選択されたページのみを読み込むことから開始し、必要に応じて追加のページを読み込みます。Figmaのマルチプレイヤーシステムは、QueryGraphを使用して、要求されたページを他のページの必要な読み込み依存関係とともにクライアントに送信します。
- プロトタイプのフレーム単位: Figmaではプロトタイプ閲覧者向けにフレーム単位で動的に読み込みます。そして一度に1画面のみが表示されます。また、Figmaは、顕著な遅延を防ぐために、設定可能な遷移数以内で現在の状態から到達できるフレームを事前読み込みします。繰り返しになりますが、QueryGraphは、Figmaファイルの必要な部分すべてがクライアントに揃っていることは保証しますが、それ以上のことはしません。
閲覧者は動的読み込みのメリットを享受してきましたが、Figmaの日々のファイル読み込みの70%は、編集可能なファイルによるものです。フレームごとにプロトタイプを動的に読み込み、ページごとに表示専用ファイルを動的に読み込むという成功の上に、同じ読み込みロジックを編集可能なファイルにも拡張したいと考えました。課題は、まだ読み込まれていないページのコンポーネントに編集が影響する場合に、読み込まれていないコンテンツ全体に変更が正しく反映されるようにすることでした。この最適化をすべての人に提供するためには、読み取り専用クライアントの既存のロジックを再利用するだけではだめでした。編集者向けに動的読み込みを有効にするには、依存関係追跡システムを拡張して新しい種類のエッジをサポートする必要がありました。

書き込み依存関係を解きほぐす
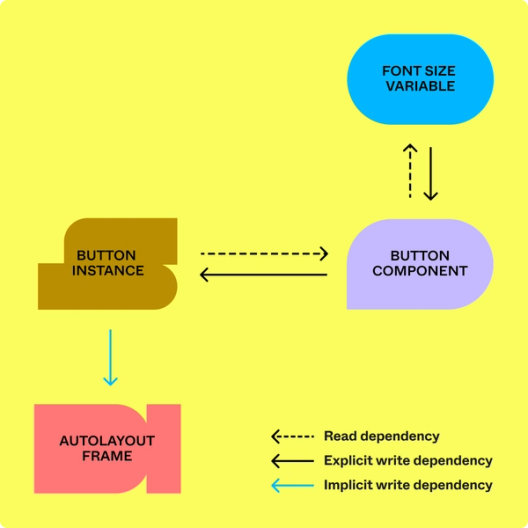
Figmaファイルの一部を表示またはレンダリングするには読み取り依存関係が必要ですが、ファイルの一部を書き込んだり編集したりするには書き込み依存関係が必要です。多くの場合、書き込み依存関係は既存の読み取り依存関係の逆です。これは、Figmaがテキストレイアウトアルゴリズムなどのコストの高い計算の結果をキャッシュするためです。スタイルが変更されると、Figmaはテキストレイアウトを再度実行し、派生データの結果をキャッシュして、いつでもレンダリングできる状態にします。たとえば、テキストスタイルがテキストレイヤーのフォントを制御する場合、それはテキストレイヤーからスタイルノードへの読み取り依存関係です。そして、その逆が書き込み依存関係です。スタイルノードはテキストレイヤーに対して書き込み依存関係があり、これはスタイルノードを安全に編集するために、Figmaが下流のテキストレイヤーを必要とすることを示しています。
これは、編集者向けの動的読み込みをサポートするために重要です。ユーザーがFigmaファイルの一部を編集する場合(テキストスタイルの変更など)、クライアントは、テキストレイヤーのキャッシュされた字形情報など、更新が必要な下流のオブジェクトすべてにアクセスできる必要があります。
以下に、Figmaのデータモデルにおける書き込み依存関係の例をいくつか示します。
- コンポーネントは、すべてのインスタンスに対して書き込み依存関係を持ち、インスタンスは他のページに存在する可能性があります。ユーザーがコンポーネントを編集すると、Figmaはコンポーネントのインスタンスでキャッシュを反映して更新する必要があります。同じ関係は、テキストスタイルやバリアブルにも当てはまります。
- オートレイアウトとは、あるノードのサイズや位置を編集すると、別のノードのサイズや位置も変更される可能性があることを意味します。したがって、これも書き込み依存関係です。コンポーネントとインスタンスでは、このオートレイアウトの書き込み依存関係はページをまたぐ可能性があります(たとえば、あるページでコンポーネントを更新すると、別のページでインスタンスのサイズが変更され、その結果、インスタンスの兄弟のサイズが変更されたり、オートレイアウトのフレーム内でサイズ変更されたり、再配置されたりする可能性があります)。

テーマのバリエーション
編集者向けの動的読み込みにはさまざまなアプローチを検討する中で、明らかな最有力候補がありました。書き込み依存関係を計算することです。これは、書き込み依存関係を考慮するためにFigmaのマルチプレイヤーシステムを更新することを意味します。これは、表示専用ユーザーと読み取り依存関係に対して行ったことと類似していますが、表示専用のケースの方が本質的にリスクが低くなります。表示専用ユーザーのための読み込みロジックが間違っていた場合、閲覧者は間違ったファイルを見る可能性がありますが、ファイルの整合性自体は危険にさらされません。しかし、編集ユースケースでは、読み込みロジックに正しい依存関係が含まれていないと、データの不整合によってファイルデータが破損するリスクがあります(変更を加えても、その変更が別のページに反映されないことを想像してみてください)。書き込み依存関係を定義することの複雑さを考慮し、他の2つのよりシンプルな代替ソリューションも検討しました。遅延編集とバックフィル、およびデータモデルのオーバーホールです。
遅延編集とバックフィル
このアプローチでは、閲覧者向けの動的読み込みと同じロジックを使用して最初のページを読み込むことになります。最初のページが読み込まれると、ユーザーはその内容をパン、ズーム、インスペクトできるようになります。バックグラウンドでは、Figmaは現在と同様にファイル全体の読み込みを続けます。しかし、ファイルの残りの部分がダウンロードされるまでファイルは表示専用になるため、ユーザーが編集を行いたいときと編集を行えるときの間に遅延が生じる可能性があります。これにより、複雑な読み込みロジックも導入される可能性があります。バックグラウンドで複数ページの読み込みを継続しながら、ユーザーがあるページに移動した場合に、そのページを読み込みキューの先頭に移動できる必要があります。フレームのヒッチングやユーザーに顕著な遅延を発生させることなく、このような大量のデータをバックフィルできるようにするのは困難です。
データモデルのオーバーホール
書き込み依存関係は派生データを表します。ユーザーが依存関係を編集すると、現在のシステムではプッシュベースのモデルを使用して更新を他のノードに反映し、他のノードは派生データのキャッシュを再計算します。Figmaでは、これらのシステムを移行してプルベースのリアクティブモデルを使用することを検討しました。これにより、ユーザーは依存関係を編集する前に依存ノードを事前にダウンロードする必要がなくなります。しかし、この方法でシステムを全面的に見直すのは大変な作業になります。Figmaでは、ユーザーのために読み込み時間とメモリーの削減を迅速に実現したいと考えていましたが、このアプローチが時間枠内で実現可能とは思えませんでした。
断固として動的なアプローチ
どちらの代替案も、長期的に持続可能なソリューションでありながら、短期的にはユーザーエクスペリエンスを大幅に向上させることはできません。遅延編集とバックフィルは技術的には簡単ですが、クライアント側のメモリーは削減されません。データモデルのオーバーホールにより書き込み依存関係は不要になりますが、長期的な取り組みになります。その結果、パフォーマンス、実現可能性、ユーザーエクスペリエンスのバランスが取れた書き込み依存関係の計算を採用することになりました。この読み込みアプローチでは、Figmaは最初の読み込み時に最初のページとそのすべての読み取りと書き込みの依存関係をダウンロードします。ユーザーが他のページに移動すると、Figmaはそれらのページ(および読み取りと書き込みの依存関係)を必要に応じてダウンロードします。
依存関係の暗黙的および明示的なエンコード
これまでのQueryGraphでは、閲覧者とプロトタイプの場合、書き込み依存関係を考慮する必要がないため、読み取り依存関係エッジのみをエンコードしていました。このフレームワークを編集者に拡張するために、基礎となるデータ構造を双方向グラフに置き換えました。ファイルを動的に読み込む場合、与えられたノードの両方の依存関係セットをすばやく判断できることが重要でした。
Figmaが導入したオートレイアウト書き込み依存関係は、そうでなければ直接相互参照しないノード間の暗黙的な書き込み依存関係の一例です。これらの依存関係をグラフ内の新しいタイプのエッジとしてエンコードしました。
さらに、既存の読み取り依存関係はすべて外部キー依存関係でした。つまり、依存関係はノードデータ構造に明示的にエンコードされていました。たとえば、インスタンスノードには、依存するコンポーネントノードを検索するための外部キーを提供するcomponentIDフィールドがあります。編集者向けの動的読み込みでは、これをさらに拡張して、オートレイアウトのフレーム内のノードを編集すると隣接するノードが自動的に変更される可能性があるなど、暗黙的な書き込み依存関係をサポートする必要がありました。
リアルタイムのファイル更新のサポート
マルチプレイヤーは、クライアントのファイルの読み込みと編集に対応するために、ファイルの完全な表現と依存関係のQueryGraphの両方をメモリー内に保持します。動的なファイルの読み込みごとに、クライアントは最初の目的のページを指定し、QueryGraphはクライアントが必要とするファイルのサブセットを計算します。ユーザーがファイルを編集すると、サーバーはセッションのサブスクリプションセットとQueryGraphの関数として、各セッションにその編集を送信する必要があるかを計算します。たとえば、ユーザーがファイルの最初のページのみを読み込み、コラボレーターが別のページの長方形の塗りつぶしを更新した場合、その長方形は登録済みセットから「到達不能」であるため、最初のユーザーにはその変更は送信されません。

他のユーザーがファイルを編集すると、QueryGraphの依存関係エッジが変更される可能性があります。あるユーザーが依存関係グラフを変更すると、別のユーザーのマルチプレイヤートラフィックが著しく増加することがあります。たとえば、ユーザーがインスタンスを別のコンポーネントに入れ替えると、マルチプレイヤーは、コラボレーターがコンポーネントとそのすべての子孫(およびその依存関係)を受け取る必要があることを認識する必要があります。たとえ、最初のユーザーがそれらのノードのいずれにも触れていなくてもです。そのユーザーは、単にそれらのノードをコラボレーターに新たに「アクセス可能」にしただけであり、システムはそれに応じて応答する必要があります。
依存関係の検証
動的に読み込まれたファイルでユーザーは、ファイルが完全に読み込まれた場合とまったく同じ変更セットを生成する必要があります。編集のパリティを実現するには、書き込み依存関係のセットが完璧である必要があります。依存関係が欠落していると、クライアントが下流ノードの派生データを更新できない可能性があります。ユーザーにとって、これらのエラーは深刻なバグのように見えるでしょう。インスタンスがバッキングコンポーネントから逸脱したり、レイアウトが不正確か古くなっていたり、フォントが欠落してテキストが正しく表示されなかったりします。
Figmaでは、クライアントが、Figmaが列挙した書き込み依存関係の役割に従って厳密にノードを編集していることを確認する必要がありました。これを検証するために、長期間にわたってマルチプレイヤーをシャドウモードで実行しました。このモードでは、マルチプレイヤーはユーザーがどのページにいるかを追跡し、実行時の動作を実際に変更することなく、動的に読み込まれたかのように書き込み依存関係を計算します。マルチプレイヤーが書き込み依存関係セット外のノードへの編集を受け取った場合、マルチプレイヤーはエラーを報告します。
この検証フレームワークを使用して、最初の実装では検出できなかった依存関係を特定することに成功しました。たとえば、フレーム制約とインスタンスに関係する、複雑でページをまたぐ再帰的な書き込み依存関係を見つけました。この依存関係を適切に処理していなければ、編集によって不完全なレイアウト計算が行われていた可能性があります。シャドウ検証フレームワークにより、あらゆるギャップを特定し、追加のテストを導入し、同様のバグを回避するためにQueryGraphを更新することができました。
実際のパフォーマンス
編集者向けの動的読み込みが導入される前は、クライアントはエンコードされたFigmaファイルを直接ダウンロードでき、マルチプレイヤーシステムではメモリー内でファイルをデコードする必要がありませんでした。一方、動的ページ読み込みでは、サーバーはまずFigmaファイルをデコードし、メモリー内にQueryGraphを構築して、クライアントに対してどのコンテンツを送信するかを決定する必要があります。このデコードプロセスは時間がかかり、クリティカルパスにあるため、最適化することが重要でした。
まず、マルチプレイヤーができるだけ早くデコード処理を開始できるようにしました。Figmaがページ読み込みの最初のGETリクエストを受信するとすぐに、バックエンドはマルチプレイヤーにヒントを送信し、ファイルの読み込みが間近に迫っているためファイルの事前読み込みを開始する必要があることを通知します。このようにして、マルチプレイヤーはクライアントがWebSocket接続を確立する前でもファイルのダウンロードとデコードを開始します。この方法で事前読み込みすると、75%パーセンタイル(p75)の読み込み時間が300~500ミリ秒短縮されます。
次に、並列デコードを導入しました。これは、Figmaファイルにローオフセットを保持する最適化であり、デコード作業を複数のCPUコアが同時に処理できるチャンクに分割できます。バイナリエンコードされたFigmaファイルをシリアルでデコードすると、かなり時間がかかることがあります(最大のファイルでは5秒以上)。そのため、実際には、これによりデコード時間が40%以上短縮されます。
マルチプレイヤーシステムがクライアントに送信するデータ量を削減することは、動的なページ読み込みにとって大きな成果でしたが、クライアント側の最適化をさらに進めることで、さらに前進できると認識しました。具体的には、クライアントはインスタンスノードの子孫をメモリーにキャッシュし、ユーザーが簡単に編集およびインタラクションできるようにします。ただし、インスタンスの「サブレイヤー」は、インスタンスのバッキングコンポーネントとユーザーが設定したオーバーライドから完全に派生可能であるため、最初のファイルの読み込み時にすべてをマテリアライズする必要はありません。動的なページ読み込みの一環として、他のページ上にあるノードのインスタンスサブレイヤーのマテリアライズを延期するようになりました。これにより、読み込み時間が大幅に短縮されましたが、読み込み時にすべてのノードが完全にマテリアライズされるという前提を排除し、代わりに遅延マテリアライズをサポートするために、多数のサブシステムを更新する必要がありました。
次第に短縮される読み込み時間
私たちは、6か月にわたってユーザーグループに動的なページ読み込みをリリースし、コントロールされたA/Bテストで変更の影響を慎重に測定し、自動化されたテレメトリを監視しました。最終的に、次のような素晴らしい結果が得られました。
- ファイルサイズが前年比で18%増しているにもかかわらず、最も遅く複雑なファイルの読み込み速度が33%向上
- ユーザーが必要とするものだけをロードすることで、クライアント上のメモリー内のノード数を70%削減
- メモリー不足エラーが発生するユーザーを33%削減
私たちは読み込み時間を最適化し、メモリーを削減する機会を常に探しています。ファイルがますます大きく複雑になるにつれて、動的なページ読み込みがパフォーマンス向上の基盤となっています。このタイプの仕事に興味がある場合は、当社の募集職種をご確認ください。現在採用中です。
Andrew Chan、Andrew Swan、Darren Tsung、Eddie Shiang、Georgia Rust、Jackie Chui、John Lai、Melissa Kwan、Raghav Anandを含む、この実現に尽力いただいたすべての方々に感謝します。

